La Guida dei non principianti alla sincronizzazione dei dati con Rsync
Il protocollo rsync può essere abbastanza semplice da utilizzare per normali processi di backup / sincronizzazione, ma alcune delle sue funzionalità più avanzate potrebbero sorprendervi. In questo articolo, mostreremo come anche i più grandi accaparratori di dati e gli appassionati di backup possano brandire rsync come un'unica soluzione per tutte le loro esigenze di ridondanza dei dati.
Avviso: solo Geek avanzati
Se sei seduto lì a pensare "Che diavolo è rsync?" O "Uso solo rsync per compiti davvero semplici", potresti voler controllare il nostro precedente articolo su come usare rsync per eseguire il backup dei tuoi dati su Linux, il che dà un'introduzione a rsync, guida l'utente durante l'installazione e mostra le sue funzioni più basilari. Una volta che hai una chiara conoscenza di come usare rsync (onestamente, non è così complesso) e stai a tuo agio con un terminale Linux, sei pronto per passare a questa guida avanzata.
Esecuzione di rsync su Windows
Per prima cosa, prendiamo i nostri lettori Windows sulla stessa pagina dei nostri guru di Linux. Sebbene rsync sia costruito per funzionare su sistemi Unix, non c'è ragione per cui non si dovrebbe essere in grado di usarlo altrettanto facilmente su Windows. Cygwin produce una meravigliosa API Linux che possiamo usare per eseguire rsync, quindi vai al loro sito Web e scarica la versione a 32 o 64 bit, a seconda del tuo computer.
L'installazione è semplice; è possibile mantenere tutte le opzioni ai valori predefiniti fino a quando non si arriva alla schermata "Seleziona pacchetti".
Ora devi fare gli stessi passi per Vim e SSH, ma i pacchetti avranno un aspetto leggermente diverso quando andrai a selezionarli, quindi ecco alcuni screenshot:
Installazione di Vim:
Installare SSH:
Dopo aver selezionato questi tre pacchetti, continua a fare clic su Avanti fino al termine dell'installazione. Quindi è possibile aprire Cygwin facendo clic sull'icona che il programma di installazione ha posizionato sul desktop.
Comandi rsync: da semplice ad avanzato
Ora che gli utenti di Windows si trovano sulla stessa pagina, diamo un'occhiata a un semplice comando rsync e mostriamo come l'uso di alcuni switch avanzati può renderlo rapidamente complesso.
Diciamo che hai un sacco di file che devono essere salvati - chi non lo fa in questi giorni? Si collega il disco rigido portatile in modo da poter eseguire il backup dei file del computer e inviare il seguente comando:
rsync -a / home / geek / files / / mnt / usb / files /
Oppure, il modo in cui apparirebbe su un computer Windows con Cygwin:
rsync -a / cygdrive / c / files / / cygdrive / e / files /
Abbastanza semplice, e a quel punto non c'è davvero bisogno di usare rsync, dal momento che puoi semplicemente trascinare e rilasciare i file. Tuttavia, se l'altro disco rigido ha già alcuni file e necessita solo delle versioni aggiornate più i file creati dall'ultima sincronizzazione, questo comando è utile perché invia solo i nuovi dati sul disco rigido. Con file di grandi dimensioni e in particolare il trasferimento di file su Internet, è un grosso problema.
Eseguire il backup dei file su un disco rigido esterno e quindi tenere il disco rigido nella stessa posizione del computer è una pessima idea, quindi diamo un'occhiata a ciò che sarebbe necessario per iniziare a inviare i file su Internet a un altro computer ( uno che hai affittato, un familiare, ecc.).
rsync -av --delete -e 'ssh -p 12345' / home / geek / files / [email protected]: / home / geek2 / files /
Il comando precedente invierà i tuoi file a un altro computer con un indirizzo IP di 10.1.1.1. Elimina i file estranei dalla destinazione che non esistono più nella directory di origine, emettono i nomi dei file che vengono trasferiti così da avere un'idea di cosa sta succedendo e tunnel rsync tramite SSH sulla porta 12345.
Il -a -v -e --delete gli interruttori sono alcuni dei più basilari e comunemente usati; dovresti già sapere molto su di loro se stai leggendo questo tutorial. Andiamo oltre alcuni altri switch che a volte vengono ignorati ma incredibilmente utili:
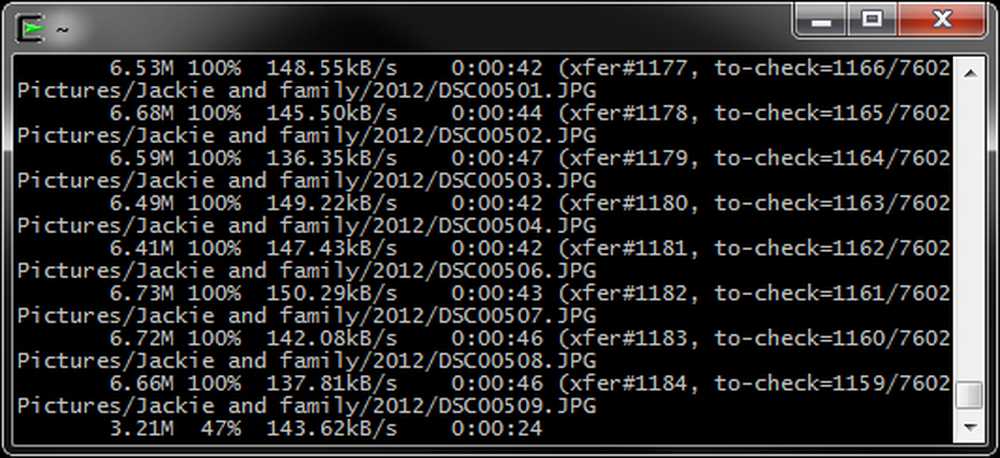
--progresso - Questa opzione ci consente di vedere lo stato del trasferimento di ciascun file. È particolarmente utile quando si trasferiscono file di grandi dimensioni su Internet, ma è possibile produrre una quantità insignificante di informazioni quando si trasferiscono piccoli file su una rete veloce.
Un comando rsync con il --progresso passare come un backup è in corso:
--parziale - Questo è un altro interruttore che è particolarmente utile quando si trasferiscono file di grandi dimensioni su Internet. Se rsync viene interrotto per qualsiasi motivo nel mezzo di un trasferimento di file, il file parzialmente trasferito viene mantenuto nella directory di destinazione e il trasferimento viene ripreso dove era stato interrotto dopo l'esecuzione del comando rsync. Quando si trasferiscono file di grandi dimensioni su Internet (ad esempio, un paio di gigabyte), non c'è niente di peggio che avere una seconda interruzione di Internet, una schermata blu o un errore umano che fa inciampare nel trasferimento dei file e dover ricominciare tutto da capo.
-P - questo interruttore combina --progresso e --parziale, quindi usalo invece e renderà il tuo comando rsync un po 'più ordinato.
-z o --comprimere - Questa opzione consente a rsync di comprimere i dati del file durante il trasferimento, riducendo la quantità di dati che devono essere inviati alla destinazione. In realtà è un interruttore abbastanza comune, ma è tutt'altro che essenziale, ma solo a vantaggio dei trasferimenti tra connessioni lente e non fa nulla per i seguenti tipi di file: 7z, avi, bz2, deb, g, z iso, jpeg, jpg, mov, mp3, mp4, ogg, rpm, tbz, tgz, z, zip.
-h o --leggibile dagli umani - Se stai usando il --progresso passa, sicuramente vorrai usare anche questo. Cioè, a meno che non ti piaccia convertire i byte in megabyte al volo. Il -h switch converte tutti i numeri emessi in un formato leggibile dall'uomo, in modo da poter effettivamente dare un senso alla quantità di dati trasferiti.
-n o --funzionamento a secco - Questo passaggio è essenziale per sapere quando stai scrivendo il tuo script rsync e provalo. Esegue una corsa di prova ma in realtà non apporta alcuna modifica - le modifiche potrebbero essere ancora eseguite normalmente, quindi puoi leggere tutto e assicurarti che sia ok prima di mandare in produzione lo script.
-R o --parente - Questo interruttore deve essere utilizzato se la directory di destinazione non esiste già. Utilizzeremo questa opzione più avanti in questa guida in modo che possiamo creare directory sul computer di destinazione con data e ora nei nomi delle cartelle.
--escludere-da - Questo interruttore viene utilizzato per collegarsi a un elenco di esclusioni che contiene percorsi di directory di cui non si desidera eseguire il backup. Ha solo bisogno di un semplice file di testo con una directory o un percorso file su ogni riga.
--include-da - Simile a --escludere-da, ma si collega a un file che contiene directory e percorsi di file dei dati di cui si desidera eseguire il backup.
--statistiche - In realtà non è un passaggio importante, ma se sei un amministratore di sistema, può essere utile conoscere le statistiche dettagliate di ciascun backup, in modo tale da poter monitorare la quantità di traffico inviato sulla rete e tale.
--log file - Ciò consente di inviare l'output rsync a un file di registro. Lo raccomandiamo sicuramente per i backup automatici in cui non siete lì a leggere l'output da soli. Lascia sempre una volta i file di registro nel tuo tempo libero per assicurarti che tutto funzioni correttamente. Inoltre, è un passaggio cruciale per un amministratore di sistema da utilizzare, quindi non ti rimane da chiedersi come i tuoi backup siano falliti mentre hai lasciato il tirocinante in carica.
Diamo un'occhiata al nostro comando rsync ora che abbiamo aggiunto alcune altre opzioni:
rsync -avzhP --delete --stats --log-file = / home / geek / rsynclogs / backup.log --exclude-from '/home/geek/exclude.txt' -e 'ssh -p 12345' / home / geek / files / [email protected]: / home / geek2 / files /
Il comando è ancora abbastanza semplice, ma non abbiamo ancora creato una soluzione di backup decente. Anche se i nostri file sono ora in due diverse posizioni fisiche, questo backup non fa nulla per proteggerci da una delle principali cause di perdita di dati: errore umano.
Backup di istantanee
Se elimini accidentalmente un file, un virus corrompe qualcuno dei tuoi file, o succede qualcos'altro in cui i tuoi file sono alterati in modo indesiderato, e quindi esegui lo script di backup rsync, i tuoi dati di backup vengono sovrascritti con le modifiche indesiderate. Quando si verifica una cosa del genere (non se, ma quando), la soluzione di backup non ha fatto nulla per proteggerti dalla perdita di dati.
Il creatore di rsync lo ha capito e ha aggiunto il --di riserva e --di backup-dir argomenti in modo che gli utenti possano eseguire backup differenziali. Il primo esempio sul sito Web di rsync mostra uno script in cui viene eseguito un backup completo ogni sette giorni, quindi le modifiche a tali file vengono eseguite quotidianamente in directory separate. Il problema con questo metodo è che per recuperare i tuoi file, devi recuperarli in modo efficace sette volte diverse. Inoltre, molti geek eseguono i loro backup più volte al giorno, quindi puoi facilmente avere oltre 20 diverse directory di backup in un dato momento. Il recupero dei tuoi file non è solo un problema, ma anche la semplice ricerca dei dati di backup può richiedere molto tempo: dovresti sapere l'ultima volta che un file è stato modificato per trovare la sua copia di backup più recente. Oltre a tutto ciò, è inefficiente eseguire solo backup incrementali settimanali (o anche meno frequenti in alcuni casi).
Backup di istantanee in soccorso! I backup di istantanee non sono altro che backup incrementali, ma utilizzano i collegamenti fisici per mantenere la struttura dei file dell'origine originale. All'inizio, potrebbe essere difficile orientarsi, quindi diamo un'occhiata a un esempio.
Fai finta di avere uno script di backup in esecuzione che esegue automaticamente il backup dei nostri dati ogni due ore. Ogni volta che rsync esegue questa operazione, denomina ogni backup nel formato di: Backup-mese-giorno-anno-tempo.
Quindi, alla fine di un giorno tipico, avremmo una lista di cartelle nella nostra directory di destinazione come questa:

Quando attraversi una di queste directory, vedresti tutti i file dalla directory di origine esattamente com'era in quel momento. Tuttavia, non ci sarebbero duplicati in nessuna delle due directory. rsync realizza questo con l'uso di hardlinking attraverso il --link-dest = DIR discussione.
Ovviamente, per avere questi nomi di directory piacevolmente datati, dovremo rinforzare un po 'il nostro script rsync. Diamo un'occhiata a cosa servirebbe per realizzare una soluzione di backup come questa, e quindi spiegheremo lo script in modo più dettagliato:
#! / Bin / bash
#copy old time.txt to time2.txt
si | cp ~ / backup / time.txt ~ / backup / time2.txt
#overwrite il vecchio file time.txt con una nuova ora
echo 'date + "% F-% I% p"'> ~ / backup / time.txt
#make il file di registro
echo ""> ~ / backup / rsync-dovrebbe + "% F-% I% p" 'log
comando #rsync
rsync -avzhPR --chmod = Du = rwx, Dgo = rx, Fu = rw, Fgo = r --delete --stats --log-file = ~ / backup / rsync-'date + "% F-% I% p "'. log --exclude-from' ~ / exclude.txt '--link-dest = / home / geek2 / files /' cat ~ / backup / time2.txt '-e' ssh -p 12345 '/ home / geek / files / [email protected]: / home / geek2 / files / 'date + "% F-% I% p"' /
# non dimenticare di scp il file di log e metterlo con il backup
scp -P 12345 ~ / backup / rsync-'cat ~ / backup / time.txt'.log [email protected]: / home / geek2 / files / 'cat ~ / backup / time.txt' / rsync-'cat ~ / backup / time.txt'.log
Quello sarebbe un tipico script rsync di istantanee. Nel caso ti abbiamo perso da qualche parte, analizziamolo pezzo per pezzo:
La prima riga del nostro script copia i contenuti di time.txt in time2.txt. Il pipe yes è per confermare che vogliamo sovrascrivere il file. Successivamente, prendiamo l'ora corrente e la inseriamo in time.txt. Questi file torneranno utili in seguito.
La riga successiva crea il file di log rsync, nominandolo rsync-date.log (dove data è la data e l'ora effettive).
Ora, il complesso comando rsync di cui ti abbiamo avvertito:
-avzhPR, -e, --delete, --stats, --log-file, --exclude-from, --link-dest - Solo gli interruttori di cui abbiamo parlato prima; scorrere verso l'alto se è necessario un aggiornamento.
--chmod = Du = rwx, Dgo = rx, Fu = rw, FGO = r - Queste sono le autorizzazioni per la directory di destinazione. Dato che stiamo creando questa directory nel mezzo del nostro script rsync, dobbiamo specificare le autorizzazioni in modo che il nostro utente possa scrivere i file in esso.
L'uso di comandi data e gatto
Esamineremo ogni utilizzo dei comandi date e cat all'interno del comando rsync, nell'ordine in cui si verificano. Nota: siamo consapevoli che ci sono altri modi per realizzare questa funzionalità, specialmente con l'uso di dichiarare variabili, ma per lo scopo di questa guida, abbiamo deciso di utilizzare questo metodo.
Il file di registro è specificato come:
~ / backup / rsync-dovrebbe + "% F-% I% p" 'log
In alternativa, potremmo averlo specificato come:
~ / backup / rsync-'cat ~ / backup / time.txt'.log
Ad ogni modo, il --log file il comando dovrebbe essere in grado di trovare il file di log datato creato in precedenza e scrivere su di esso.
Il file di destinazione del collegamento è specificato come:
--link-dest = / home / geek2 / files / 'cat ~ / backup / time2.txt'
Ciò significa che il --link-dest comando è data la directory del backup precedente. Se eseguiamo backup ogni due ore e sono le 4:00 PM al momento in cui abbiamo eseguito questo script, allora il --link-dest comando cerca la directory creata alle 14:00 e trasferisce solo i dati che sono cambiati da allora (se presenti).
Per reiterare, ecco perché time.txt viene copiato in time2.txt all'inizio dello script, quindi il --link-dest il comando può fare riferimento a quel momento più tardi.
La directory di destinazione è specificata come:
[email protected]: / home / geek2 / files / 'date + "% F-% I% p"'
Questo comando mette semplicemente i file sorgente in una directory che ha un titolo della data e ora correnti.
Infine, ci assicuriamo che una copia del file di log sia posizionata all'interno del backup.
scp -P 12345 ~ / backup / rsync-'cat ~ / backup / time.txt'.log [email protected]: / home / geek2 / files / 'cat ~ / backup / time.txt' / rsync-'cat ~ / backup / time.txt'.log
Usiamo la copia sicura sulla porta 12345 per prendere il log rsync e posizionarlo nella directory corretta. Per selezionare il file di registro corretto e assicurarsi che finisca nel posto giusto, il file time.txt deve essere referenziato tramite il comando cat. Se ti stai chiedendo perché abbiamo deciso di cat time.txt invece di usare semplicemente il comando date, è perché molto tempo sarebbe potuto accadere mentre il comando rsync era in esecuzione, quindi per essere sicuri di avere il momento giusto, siamo solo cat il documento di testo che abbiamo creato in precedenza.
Automazione
Usa Cron su Linux o Task Scheduler su Windows per automatizzare lo script rsync. Una cosa che devi fare attenzione è assicurarti di terminare qualsiasi processo rsync attualmente in esecuzione prima di continuarne uno nuovo. L'Utilità di pianificazione sembra chiudere automaticamente le istanze già in esecuzione, ma per Linux è necessario essere un po 'più creativi.
La maggior parte delle distribuzioni Linux può usare il comando pkill, quindi assicurati di aggiungere quanto segue all'inizio dello script rsync:
pkill -9 rsync
crittografia
No, non abbiamo ancora finito. Finalmente abbiamo una soluzione di backup fantastica (e gratuita!), Ma tutti i nostri file sono ancora suscettibili di furto. Spero che tu stia salvando i tuoi file in qualche posto a centinaia di chilometri di distanza. Non importa quanto sia sicuro quel posto lontano, il furto e l'hacking possono sempre essere problemi.
Nei nostri esempi, abbiamo tunnelato tutto il nostro traffico rsync tramite SSH, quindi significa che tutti i nostri file sono crittografati mentre sono in transito verso la loro destinazione. Tuttavia, dobbiamo assicurarci che la destinazione sia altrettanto sicura. Tieni presente che rsync crittografa solo i dati mentre vengono trasferiti, ma i file vengono aperti una volta raggiunta la destinazione.
Una delle migliori caratteristiche di rsync è che trasferisce solo le modifiche in ogni file. Se hai tutti i tuoi file crittografati e fai una piccola modifica, l'intero file dovrà essere ritrasmesso come risultato della crittografia che ha completamente randomizzato tutti i dati dopo ogni cambiamento.
Per questo motivo, è meglio / più semplice utilizzare un tipo di crittografia del disco, come BitLocker per Windows o dm-crypt per Linux. In questo modo, i tuoi dati sono protetti in caso di furto, ma i file possono essere trasferiti con rsync e la tua crittografia non ne ostacolerà le prestazioni. Ci sono altre opzioni disponibili che funzionano in modo simile a rsync o addirittura ne implementano qualche forma, come Duplicity, ma mancano alcune delle funzionalità che rsync ha da offrire.
Dopo aver configurato i backup dell'istantanea in una posizione fuori sede e crittografato i dischi rigidi di origine e di destinazione, datti una pacca sulla spalla per padroneggiare rsync e implementare la soluzione di backup dei dati più infallibile possibile.